A few days back, reading the article on the Moore's law, I thought it is not too difficult to extend this for an analogous situation, e.g. the amount of data being cached by a search engine like Google also grows exponentially. With changing times we need to have solution that would adapt to the changing data requirements and availability solutions like virtual infinite scale-out like cloud. Even though virtualization is not exactly a database concept, it's not long when we will have it as a standard for RDBMS. This article is however about using MySQL replication to scale out reads and make it fault-tolerant.
An effective way of monitoring and managing the clients is to create a layer that monitors the topology and send out the read an write queries to the master-slave(s) system.
Essentially this layer will have three modules, the load-balancer, the connection pool manager and the topology monitor. As the name suggests load balancer balances the read loads on various slaves, the connection pool manager holds the records of connection to various servers, and the topology monitor monitors the systems and does an automatic failover sequence (as described earlier) to restore the system to a working condition with no or minimal loss of data.
MySQL replication is essentially asynchronous i.e. it doesnot guarantee zero latency between the master and the slave(s). This, by extension means that in case of a master crash, data may be lost if we decide to promote one of the slave to be the master and that is why while scaling out reads we need to take care of this. A general design for master-slave(s) configuration with reads scaled out will be like this.
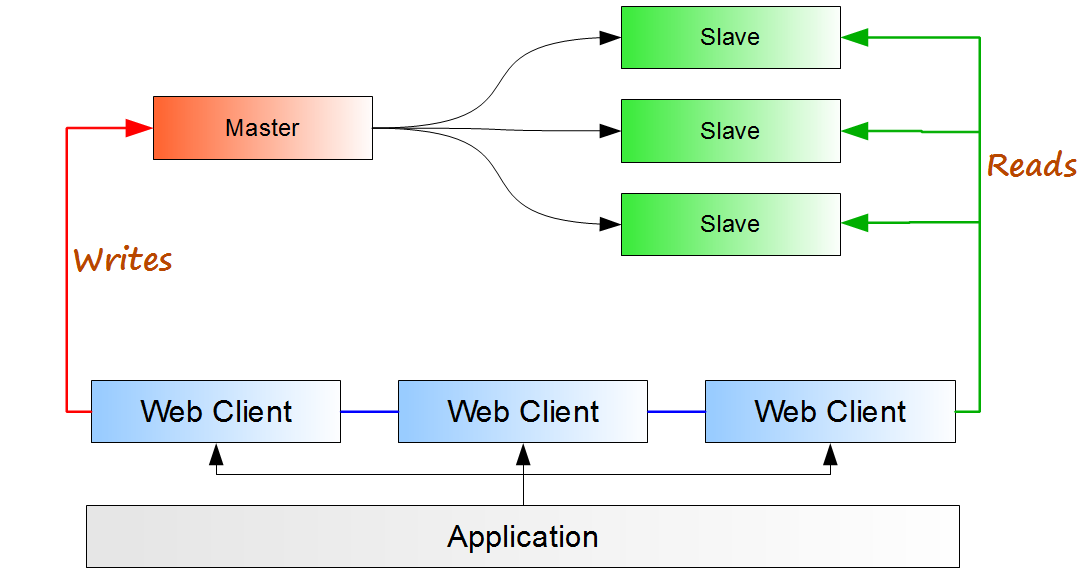 |
| MySQL Replication design: read off-loading |
In the above diagram the application connects to the web clients connected to the replication setup. The web clients segregate the queries into "read" or "write". This enables the web-clients to redirect the reads to the slave and the writes to the master, effectively off-loading the master. This improves the performance and enables read-intensive tasks like reporting and consolidation application to run without hampering the performance of the master. A problem can however happen if the master has a lot of writes happening there-by causing the slaves to be loaded as well.
Fault Tolerant Systems: One of the basic requirement of a modern-day system is fault tolerance. Master and slave(s) system is capable of tolerating faults caused due to failures on the master. This, however requires the DBA (or an external program) to monitor any such failures and promoting the (most up-to-date) slave to take up the role of the master and changing the topology by re-configuring the slaves to take updates from the new master.
An effective way of monitoring and managing the clients is to create a layer that monitors the topology and send out the read an write queries to the master-slave(s) system.
 |
| Virtual layer for interaction between the RDBMS and the Application |
Essentially this layer will have three modules, the load-balancer, the connection pool manager and the topology monitor. As the name suggests load balancer balances the read loads on various slaves, the connection pool manager holds the records of connection to various servers, and the topology monitor monitors the systems and does an automatic failover sequence (as described earlier) to restore the system to a working condition with no or minimal loss of data.
No comments:
Post a Comment